
Big Data had been around as a buzz word for some time now but still, there are confusions about what exactly it is, especially for people who are not involved directly in technical departments. It can be due to lack of leadership sophistication around the concept and its associated possibilities. Big Data: A Beginner’s Guide for Non-Technical People is a guide to address that. We will go through the core concepts and ideas behind Big Data and I will try to keep it jargon free and simple.
[two_first]1. Introduction
The concept of Big Data and the whole Big Data Ecosystem is continuing to evolve with time and is a driving force behind a lot of latest technologies like Artificial intelligence, Data Science, Machine and Deep learning, Internet of Things (IOT) and Digital Transformation.
In the last couple of decades, with computers, internet, smartphones becoming a common everyday commodity, we started generating more and more data every passing day. Today whatever we do have some kind of digital footprint and generates data, for example, text messages, GPS, payment transactions, social media posts etc. Sensor technologies in industries are other major sources of data being generated. The use of sensors in a typical factory increased ten folds in the last couple of years. Machines and devices in factories are equipped with all kinds of sensors nowadays which generates proportional data. All this data contribute to peta-bytes of data we are generating everyday.
[/two_first] [two_second]
[/two_second]
2. What is Big Data
Big Data is the extremely large amount of data being generated by people, machines, sensors etc which require new and scalable technologies to handle the data as traditional systems are not able to cope with the requirement we have with this type of data. But the amount of data is not the only reason, velocity of the data and the speed with which we need to process this data is also a reason we need scalable and distributable technologies.
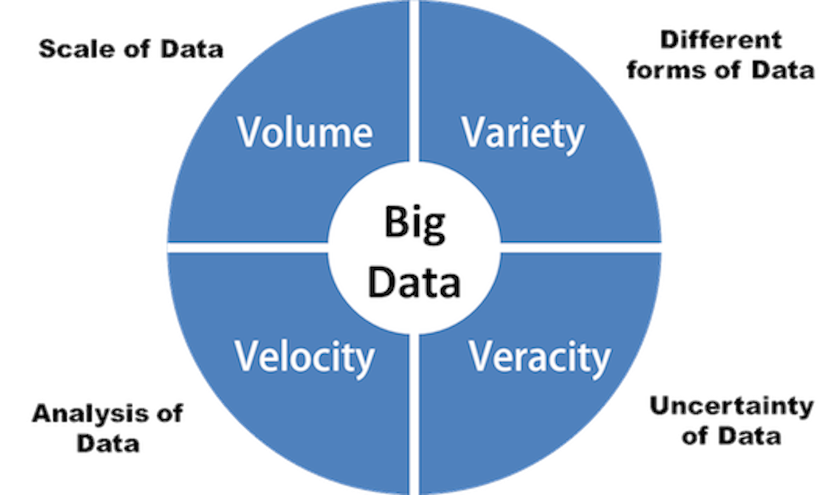
Big Data is typically characterized by the four V’s:
- Volume: The amount and scale of data being created every day is vast compared to traditional data sources we had in the past.
- Variety: The data comes from different sources in different structures and forms. Data is now being created not only by us people but by machines, sensors etc.
- Velocity: The speed with which data is being generated and the speed with which we need this data to be processed. Data is generated extremely fast, the process that never stops even while we sleep. Single instance of high-velocity data is Twitter where over 350,000 tweets are now sent worldwide per minute, equating to 500 million tweets per day.
- Veracity: Big Data is sources from many different places, as a result we need to test the veracity/quality of the data.
3. What can Big Data Do?
The amount of data we have now can be processed to find insights which were not even possible some years back. Some of the fields where Big Data is being used and in fact help businesses are:
- Consumer Services: Make everyday lives easier and more convenient. For instance, social media, e-commerce, gaming, financial transactions etc.
- Healthcare: Healthcare data-driven medicine involves analyzing vast number of medical records and images for patterns which can help spot diseases early and develop new medicines.
- Space Exploration: NASA and other space organizations analyze millions and millions of data points to make models. These models are then used for the operations like perfect environment to land rovers on other planets, to figure out atmosphere on other planets etc.
- Help in Disasters: Data especially the sensors data is and can be analyzed to predict where earthquakes are likely to strike next. Besides this other data can be analyzed to prevent or to respond to natural as well as man-made disasters.
- Preventing Crime: Police forces across the world are increasingly adopting the big data analysis to predict and implement strategies to deploy resources more efficiently and act as a deterrent where one is needed.
4. How does Big Data work?
Big Data is the major force behind Data Science. Data Science works on the principle that more we know about anything and more data we have, we can analyze it and patterns will start to emerge.
So all this data which we need is available in structured, semi-structured as well as unstructured format, which means it cannot be easily turned into insight. So we need to clean, transform and structure all this data based on the requirements. A lot of this data can also be in the format of pictures, videos, audio as well as multiple formats of text. To make sense of all this, Big Data projects often involve making use of the cutting edge technologies like Machine Learning. If we can teach computers how to process and make sense of the data using image recognition or natural language processing etc, computers can be more efficient and fast in pattern detection than humans.
Now, obviously to process and store all this data we need resources. This is what gave rise to organizations providing Big Data tools and stack through “as-a-service” platforms. Businesses can rent these services and use the storage and processing power from these platforms for Big Data and pay for the service. This model is making Big Data-Driven discovery and transformations accessible to any organization and cuts out the need to spend vast sums on hardware, software, premises and technical stuff.
5. What are the concerns of Big Data?
With all the advancements and insights Big Data provides us, it also comes with some concerns:
- Data Privacy: With increasing digitalization the amount of data we share contains a lot of private data which we might not like to share. We as a consumer have to strike a balance between what we are comfortable sharing versus the personalized services provided by the Big Data-Driven companies and services.
- Data Security: With all this data being shared across platforms and services, we can never be sure if our data is secure or not. The legal data protections laws still lack some details when it comes to personal data security. Every once in a while we hear about some hack where the companies compromised user data up to large extent.
- Data Discrimination: The more data we share about our lives, easier it is for organizations to discriminate people based on the data from their lives. Financial institutions already use these kinds of data to make decisions about whether we can take some credit, loan or other such services or not. With more data available, this kind of scrutiny will also increase.
6. How is Big Data used in Data-Driven Organizations
Data-Driven Organizations working with Big Data uses Hadoop Stack. Hadoop being the poster boy of the whole Big Data Ecosystem. The Hadoop Stack which started with just Hadoop Map-Reduce and HDFS has expanded to include a lot of other technologies and frameworks.
Three distinct scenarios how Big Data is being used in Enterprise Data Management are:
- Big Data as an ETL and Filtering Platform: One of the biggest challenges with Big Data is extracting valuable information from a lot of noise filled data. Hadoop stack can read in the raw data, apply appropriate filters, implement required logic and output a summary or refined data set. This is what ETL is and moreover, this output data can further be used as an input layer for analysis, BI, reporting or even using more traditional systems like SAS.
- Big Data as an exploration engine: Once the data is in Big Data cluster and is filtered and cleaned ready to be used, it can be added to the existing pile of analytics-ready data without having the need to re-index all the data again. This newly appended data along with the old one is always available to corporation to make use of.
- Big Data Cluster as a Data Archive: Most of the historical data after certain years need not be available for use in the environment. The traditional way of archiving data is with the use of tape or disk, but in case this data is needed for some reason it is extremely painful and time consuming to reload all data back in the storage for use. Big Data clusters can change this, the storage is comparatively cheap in distributed clusters which can allow us to keep all that data in the cluster without the need to archive and clean the cluster storage.
7. The Hadoop Stack
Do not confuse Apache Hadoop with Hadoop Stack. The whole Big Data ecosystem started with the development of Apache Hadoop as a Technology but in the last decade, a lot of new technologies and projects were created and added to the stack but the name just stuck around thus the stack being called Hadoop Stack. Hadoop is the poster boy of the whole Big Data Ecosystem.
All the projects and technologies are available individually from Apache Software Foundation as Open Source (also called Vanilla distributions) but there are companies like Hortonworks, Cloudera, and MapR which sell a subset of these technologies as a single stack. Hortonworks calls this stack Hortonworks Data Platform (HDP), Cloudera’s stack is called Cloudera’s Distribution of Hadoop (CDH) and MapR’s stack is called Converged Data Platform (CDP).
All the companies provide some of their proprietary components in their offerings but most basic components of Hadoop Stack are same. The basic setup of the Hadoop Stack is as shown in the diagram below:
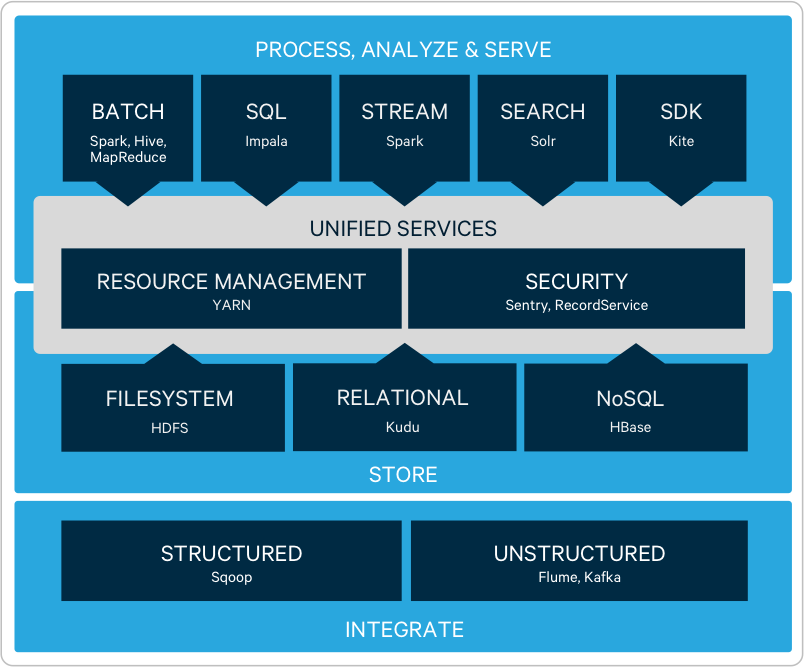
Following are the components of the most basic Hadoop Stack:
- Apache Hadoop: Apache Hadoop is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. Apache Hadoop project includes 4 sub-projects; they are:
- Hadoop Common: Consists of common utilities that support other Hadoop realted projects.
- Hadoop Distributed File System (HDFS): A distributed file system that provides high-throughput access to application data.
- Hadop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
- Apache Hive: Apache Hive is a component which facilitates reading, writing, and managing large datasets residing in distributed storage using SQL like langauge called HiveQL. A command line tool and JDBC driver are provided to connect users to Hive.
- Apache Spark: Apache Spark is a general purpose distribute processing system. It is one of the most powerful component which provides batch as well as streaming processing capabilities.
- Apache Impala: Apache Impala is an open source, native analytic database on top of Apache Hadoop. Impala is avaialble as a part of Cloudera’s and MapR’s stack
- Apache SOLR: Apache SOLR is open source enterprise search platform which is built on top of Apache Lucene.
- Apache Kafka: Apache Kafka is a distributed streaming platform which was develope initially by LinkedIn and later contributed to the Apache Foundation. Apache Kafka is industry standard in building real-time streaming data pipelines or applications.
- Apache HBase: Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google’s Bigtable. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
These are the basic components of any Hadoop based stack. There can be some additions or subtractions from the list based on the specific requirements of the organizations but this remains the fairly standard Hadoop Stack.
8. End Notes
This is all we are going to discuss in this article to give you an overview of Big Data.
When people and organizations initially started to hear about Big Data some years back, it was sometimes dismissed as a fad or trend which will go away in few years. But this hadn’t proven to be the case yet. In fact, a lot of new technologies are being developed which are based on top of Big Data and Hadoop. The amount of data available to use is only going to increase day by day, so it is time for the organizations to take advantage of Big Data and make the switch.